I was recently developing a small app that used a Google Maps heavily and since I was quite new to the subject of using Google Maps API I had to educate myself to the subject of setting them up. What I found interesting was that there are plenty of tutorials about how to create a simple page with a map and manipulate it from your Javascript (for instance jQuery and Google Maps Tutorial: #1 Basics) but they all talk about Google Maps 2.x and I couldn’t find a decent one for 3.0. So I decided to write one myself, just to keep track of what needs to be done. Since google openly marks 2.x API as obsolete I hope someone might find it usefull during the inevitable migration. This will be heavly influenced by Marc Grabanski’s tutorial, so I give a lot of credit for this post to him. If you run into problems, this page is your best friend
Get Google Maps and jQuery
Add following script tags to your page (I’m gonne use jQuery here, but obviously it’s not mandatory to make Maps work):
<script type="text/javascript" src="http://maps.googleapis.com/maps/api/js?sensor=true"> </script>
<script type="text/javascript" src="http://ajax.aspnetcdn.com/ajax/jQuery/jquery-1.7.min.js"> </script>
Obviously you can get the scripts from anywhere you want, and you might want to download them instead of using CDN. I just find this way the easiest and that’s how I want to keep things in this example.
Create a container
We need to put our map in something, so I’ll just create a div in middle of page:
<body>
<div id="main" style="width:100%; height:100%"> </div>
</body>
Make sure you specify the size of your div, otherwise you won’t see any map[1].
And since we’ll need some javascript to manipulate map, I’m going to add a script file to page:
<script type="text/javascript" src="/mapsTutorial.js"></script>
and create an empty, for now, file named mapsTutorial.js. You could add this script inside your html file, but that would make grandba Crockford cry.
Loading the map
Next I’m going to use jQuery document ready event to do all the hard work and load Map object into the previously prepared DIV. Type this into mapsTutorial.js
$(document).ready(function () {
var containerId = '#main';
//create map centre point
var latitude = 50.007656;
var longitude = 19.95276;
var startPoint = new google.maps.LatLng(latitude, longitude);
//create default map options
var mapOptions = {
zoom: 8,
center: startPoint,
mapTypeId: google.maps.MapTypeId.ROADMAP
};
//create a map object
var map = new google.maps.Map($(containerId)[0], mapOptions);
});
If you’ve done everything righ so far, you should see a map spanning on whole page.
Ok, so what exactly happens there? I create google.maps.LatLng passing an arbitrary latitude/longitude[2] to its constructor, this will be the central point of my map. I choose to center it around a beautiful city of Krakow, Poland. You can use any coordinates you want, iTouchMap might help you find coordinates of a desired place. Then you create a typical options object:
var mapOptions = {</code>
zoom: 8,
center: startPoint,
mapTypeId: google.maps.MapTypeId.ROADMAP
};
Passing it zoom level, our starting point and map type (as on any google map, we can select from HYBRID, ROADMAP, SATELLITE, TERRAIN). In the end we create google.maps.Map passing reference to our DIV container and the options object.
var map = new google.maps.Map($(containerId)[0], mapOptions);
You probably not using Google Maps just to show a pretty map on your page, you want to mark some locations on it. To do that we’ll need to create a google.maps.Marker object and add it to our map. But first we’ll need some points to present, for the purpose of this tutorial I’m going to write a simple function that will generate a list of (lat, lng) points around our selected starting point. Add following code to your script:
function generateRandomLocations(map, startingPoint, count) {</code>
var locations = [];
for (var i = 0; i < count * Math.random() + 2; i++) {
locations.push({
lat: startingPoint.lat() + startingPoint.lat()*0.1 * Math.random(),
lng: startingPoint.lng() + startingPoint.lat()*0.1 * Math.random()
});
}
return locations;
}
I’m not going into detail describing this function, all it does is generate random (2, count+2) number of locations that are not more then 10% off our startingPoint’s location. Then we can write a function that will iterate on this list and add a marker for each location. I’m splitting this operation into 2 functions on purpose, as I assume you won’t generate random points in your production app and that way you’ll be able to reuse createMarkers function to process locations returned from server.
function createMarkers(map, locations) {</code>
for (var i = 0; i < locations.length; i++) {
var location = locations[i];
var point = new google.maps.LatLng(location.lat, location.lng);
var marker = new google.maps.Marker({
position: point,
map: map
});
}
}
As you can see each Marker is created using a (lat, lng) point created in previous step, our map object. As you probably already figured out it’s setting the ‘map’ property of Marker object to parent map makes him appear in right spot. If you ever wanted to remove marker from map, just set his map property to null. More on Marker object can be found here.
Last step will be to call both functions inside our document.ready event. Final version will look like this:
$(document).ready(function () {</code>
var containerId = '#main';
//create map centre point
var latitude = 50.007656;
var longitude = 19.95276;
var startPoint = new google.maps.LatLng(latitude, longitude);
//create default map options
var mapOptions = {
zoom: 8,
center: startPoint,
mapTypeId: google.maps.MapTypeId.ROADMAP
};
//create a map object
var map = new google.maps.Map($(containerId)[0], mapOptions);
var locations = generateRandomLocations(map, startPoint, 10);
createMarkers(map, locations);
});
And as a result you should see:
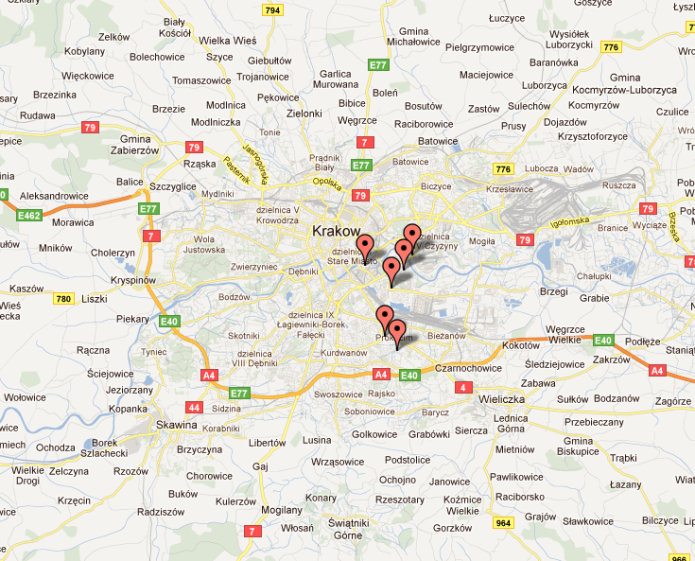
Last part I want to touch here is presenting some dialog so that you can tell user why this location is so important that you decided to put a marker on it. The easiest way to do this would be to use the default Google Maps dialog, called InfoWindow. All we really need to add to our simple page is attach event click handler to each marker, that will open a window over him and present a custom message. We’ll do both inside our createMarkers function:
function createMarkers(map, locations) {
var message = 'Hello World';
var infowindow = new google.maps.InfoWindow({
content: message,
maxWidth: 100,
});
for (var i = 0; i < locations.length; i++) {
var location = locations[i];
var point = new google.maps.LatLng(location.lat, location.lng);
var marker = new google.maps.Marker({
position: point,
map: map
});
google.maps.event.addListener(marker, "click", (function (map, marker, point) {
//return handler function with current marker bound to closure scope
return function()
{
//set info window content
infowindow.setContent('Hello world from ' + point.lat() + ', ' + point.lng());
// open window attached to this marker
infowindow.open(map, marker);
};
})(map, marker, point));
}
}
Two words of comment here, first to attach an event handler to any object from Google Maps API you use following syntax:
google.maps.event.addListener(marker, "event_name", handler_function);
Again excellent guide on events can be found on Google pages.
The second comment is about the click handler. Can you tell why we have to use this weird function returning function? It’s the only way to avoid binding the last marker to each handler’s scope and ending up with window always opening over the same marker, not matter which one user selected. Thanks to that neat trick the outer function is called with current value of iterated variable, so the result of this call is inner function with a scope bound to current marker, not last one! Final effect should look more or less like this:
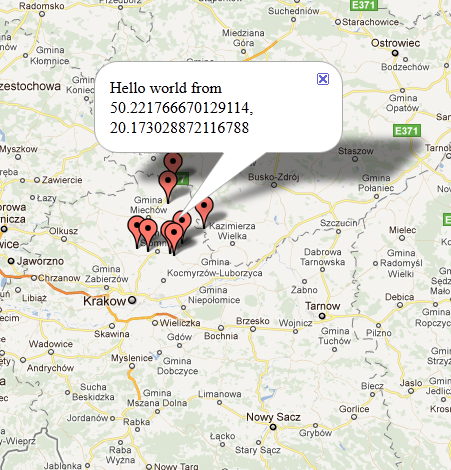
In most cases you really want to create a custom dialog, so that you can control the presentation of your popup, but thanks to the fact that InfoWindow’s content can be set to any html or DOM object it is so flexible that it should be good enough for most cases. Plus it has advantage for being really recognizable to most users who ever used Google Maps. More on InfoWindows can be found on InfoWindows API page
I’m going to stop here, though there is plenty more to it as you can imagine. Live demo of this example can be seen here. I might write a follow up to show some more advanced tricks like geocoding, geolocation API etc. Let me know if you’re interested.
[1] And you might run into some weird errors like: “a not defined” in fromLatLngToPoint function
